NLP基础知识
自带库
- NLTK:英文的库
- jieba:中文的库
文本处理流程
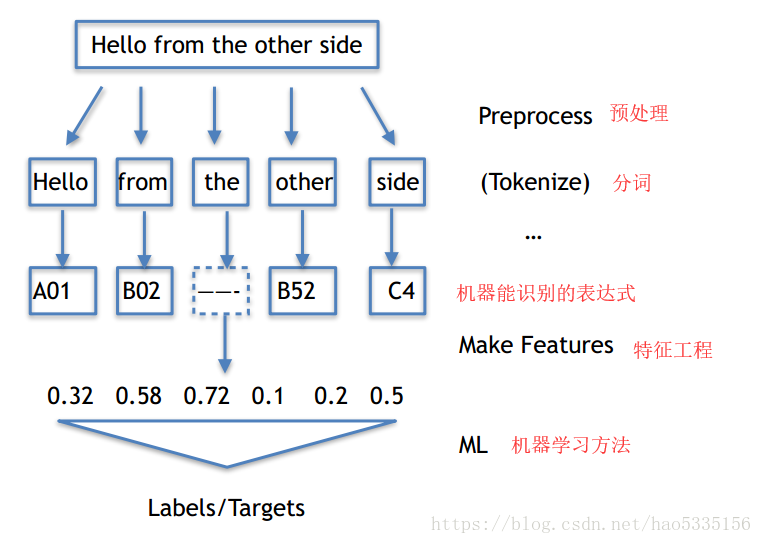
分词
英文用NLTK,中文用jieba,比较难处理的时候可能要借助正则表达式
复杂的词形
- 1、inflection变化:不影响词性
- walk->walking->walked
- 2、derivation引申:影响词性
- nation(n)->national(adj)->nationalize(v)
词形归一化
1、Stemming词干提取:把不影响词性的后缀去掉
walking->walk
walked->walk
2、Lemmatization词形归一:把各类型的词变性,归一
went归一成go
are归一成be
3、Lemmatization出现的问题(借助词性标注完成)
比如原本是are–>are,is–>is
标注后are(v)–>be,is(v)–>be
去除停用词
比如中文的:的,地,得
比如英文的:the,this
NLP实例
情感分析
数据
s1=’this is a good book’
s2=’this is a awesome book’
s3=’this is a bad book’
s4=’this is a terrible book’
把数据变成向量
统计上文出现过的所有单词:this、is 、a 、good 、awesome、 bad、 terrible、 book,然后每个样本的词向量就是这个单词是否出现过
如:s1=[1 1 1 1 0 0 0 1]
训练
然后再用ML方法训练
文本相似度
| we | you | he | work | happy | are |
|---|---|---|---|---|---|
| 1 | 0 | 3 | 0 | 1 | 1 |
| 1 | 0 | 2 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 | 0 | 0 |
这里一共表示了三个样本,然后我们提取出对应的词向量,然后用一些求两个向量的相似度的方法来计算文本的相似度,比如余弦相似度
文本分类
TF-IDF概念
- TF:Term Frequency,用来衡量一个term在文档中出现得有多频繁
- $TF(t)={t出现在文档中的次数\over 文档中的term总数}$
- IDF:Inverse Document Frequency,衡量一个term有多重要
- $IDF(t)=ln(\frac{文档总数}{含有t的文档总数})$
- $TF-IDF=TF*IDF$(注意这个是杠“-”)
TF-IDF实例
⼀个⽂档有100个单词,其中单词baby出现了3次;且一共有10M的⽂档, baby出现在其中的1000个⽂档中。
$$
TF(baby)={3\over 100}=0.03\
IDF(baby)=ln({10000000\over 1000})=4\
TF-IDF(baby)=TF(baby)IDF(baby)=0.034=0.12
$$