LSTM学习小记
RNN缺点:对所以信息都进行了存储,数据没有选择性,计算量大;梯度衰减严重。基于以上缺点。X0、X1与输出h t+1之间的距离太长,RNN对长时间记忆有明显的不足。提出了LSTM网络。

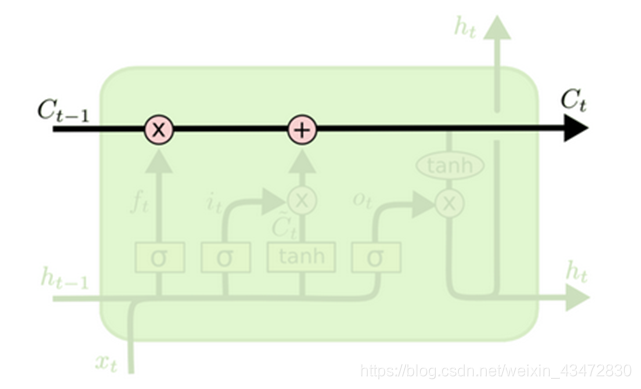
C:控制参数。决定什么样的信息会被保留什么样的会被遗忘。C值与输出相乘决定遗忘的多少。C的范围为[0,1],当C=0时,全部遗忘;当C=1时,全部记忆;当C=0.5时,部分记忆。

- 细胞更新的路线。
- 两个粉色圈表示信息进行一些基础的运算,在h循环更新的过程中,细胞C的信息也在不断更新。由于细胞C只是进行一些简单的运算,所以它的信息可以在流通中保持大体不变。
- 于标准RNN网络,h是随着时间不断更新的。在LSTM网络中新加了一个循环点:细胞C。 细胞C随着时间流动带来了长期的记忆。
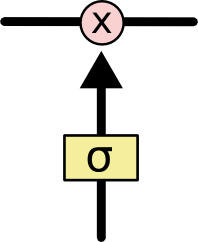
- 这样的结构称为LSTM的”门“结构,可以控制信息的进出。黄色方框里面是一个sigmoid函数。
遗忘–选择忘记过去的某些信息
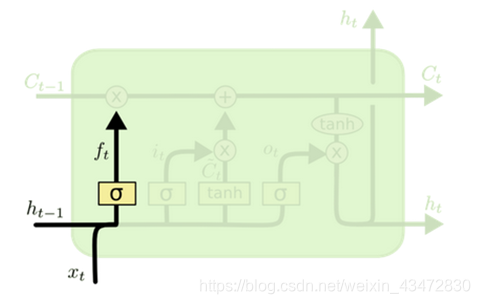
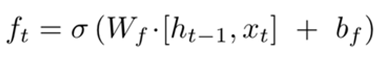
- 理解:并不是全部信息都要记住的,需要选择性遗忘。上一层的输入和本层的输入通过sigmoid函数变成一个取值在[0,1]的值,0表示完全遗忘,1表示必须记住。再通过“X”乘法操作与上层数据汇合。这里被称为遗忘门。—
forget gate [x,y]是把x和y合并在一起。$W_f,b_f$当然是学习出来的参数,下面的也一样。
输入:选择记忆现在的某些信息
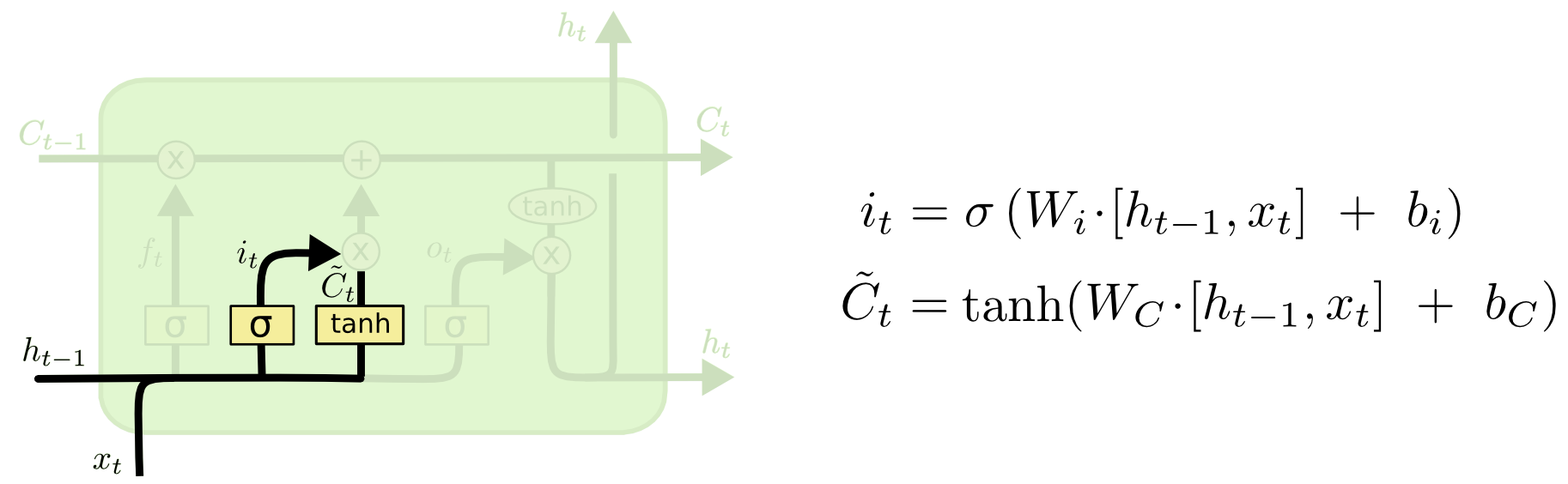
- 理解:将输入的信息分别通过sigmoid函数和tanh函数的处理,共同输入到“X”乘法运算中。同样的Sigmoid函数仍然输出一个[0,1]的值,表示该数据的可以记忆的价值是多少。tanh发挥的作用类似于RNN中发挥的作用,输出一个候选值,其实sigmoid和tanh都是做一个线性变换。由Sigmoid函数决定该值要记忆多少。这里被称为输入门
- $C_t$表示第t个细胞的候选的信息,$\widetilde{C_t}$表示候选细胞。细胞及当前状态信息。$C$负责传递下去,而$h$负责当前状态的输出。
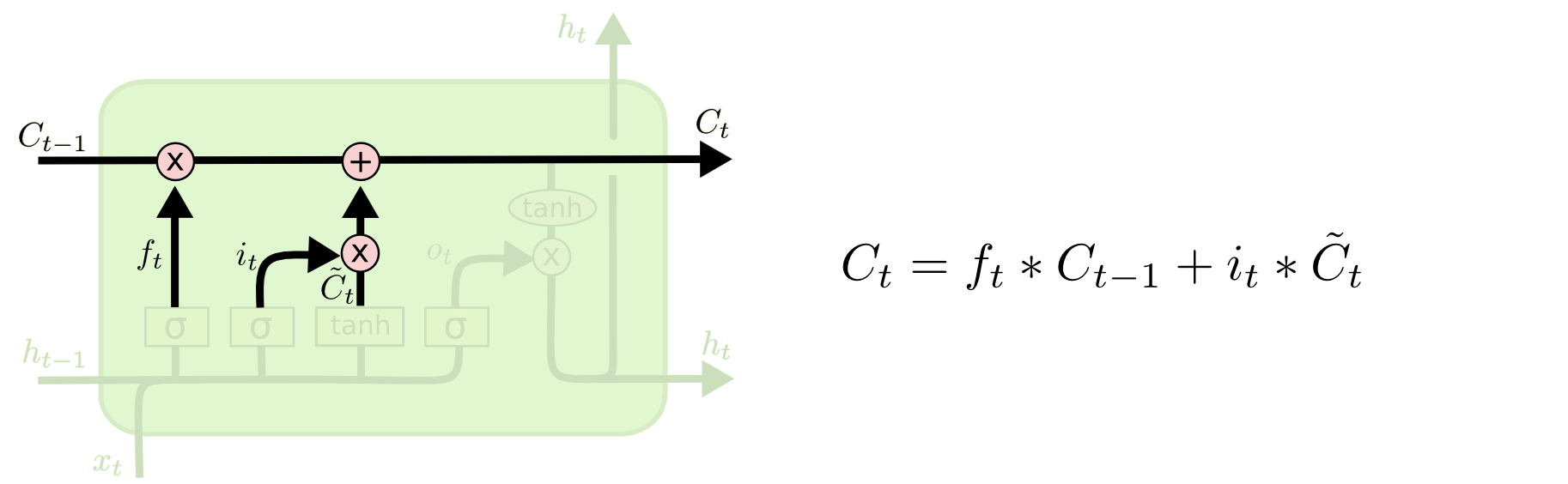
合并:将过去的记忆和现在的记忆合并在一起
理解:两端记忆分别通过乘法后用加法运算合并到一起。
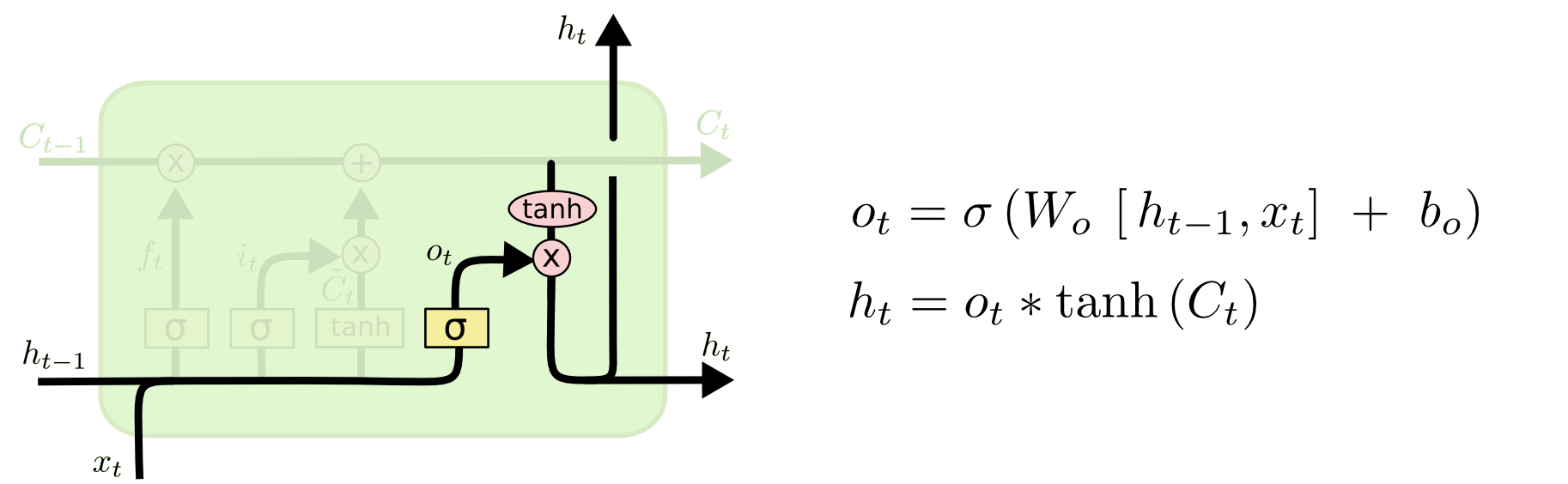
输出
理解:最后把合并的细胞信息通过tanh函数与sigmoid的输出相乘,得到最终的输入,进入下一个神经元中。这里称为输出门。
在整个过程中,sigmoid函数起的是选择作用。 通过输出的值控制记忆的记忆程度。tanh起的是变换作用,与RNN中的作用类似。此外,LSTM还有其他变体,但是根据测试各个变体之间的差距很小。
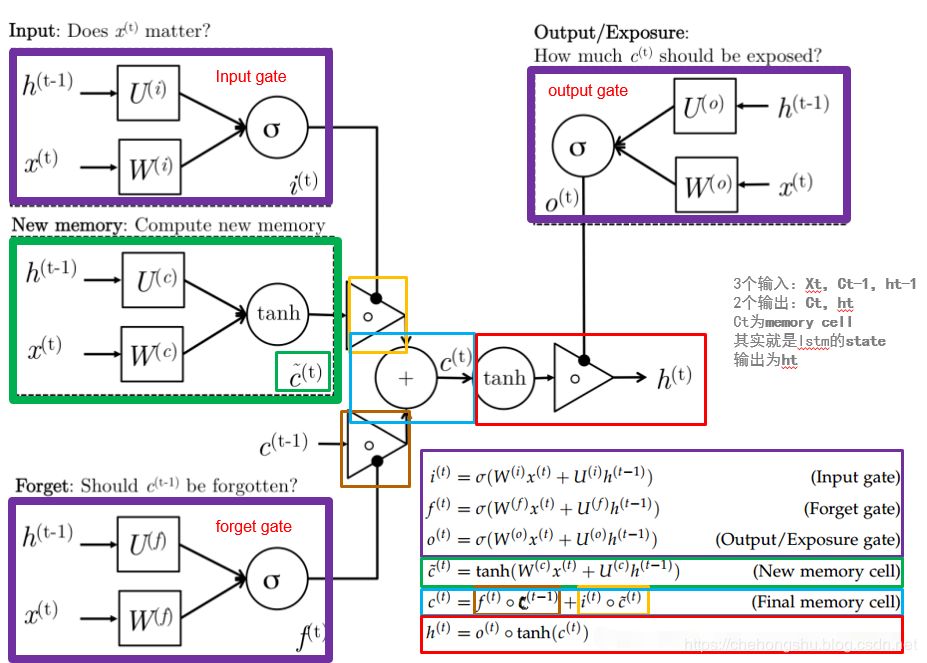
LSTM解决的问题
原始的RNN因为结构在经过hidden state的反向传播的时候会乘上sigmoid的导数值,容易引发梯度爆炸或梯度消失
而LSTM通过门机制解决了这个问题(遗忘门,输入门,输出门)
- $$
遗忘门:f_t=\delta(W_f\cdot[h_{t-1},x_t]+b_f)\
输入门:i_t=\delta(W_i\cdot[h_{t-1},x_t]+b_i)\
输出门:o_t=\delta(w_o\cdot[h_{t-1},x_t]+b_0)\
当前单元状态c_t:c_t=f_tc_{t-1}+i_ttanh(w_c\cdot[h_{t-1},x_t]+b_c)\
当前时刻的隐层输出:h_t=o_t*tanh(c_t)
$$
- $$
- 老实说,如果解决问题网上说法不一,作者也只是抽象的简化模型,这里不做叙述
BiLSTM
- 双向LSTM,就是对于输入的信息,正向和反向同时建立一个LSTM,然后把hidden layer拼接在一起

- 如上,用BiLSTM编码句子”我爱中国”
- BiLSTM要比LSTM训练更多次才能趋向稳定,但是可以获得更好的稳定性和准确率。但是要很多次才能稳定,要花很多时间,所以小问题上用的不是很多
LSTM变体——GRU
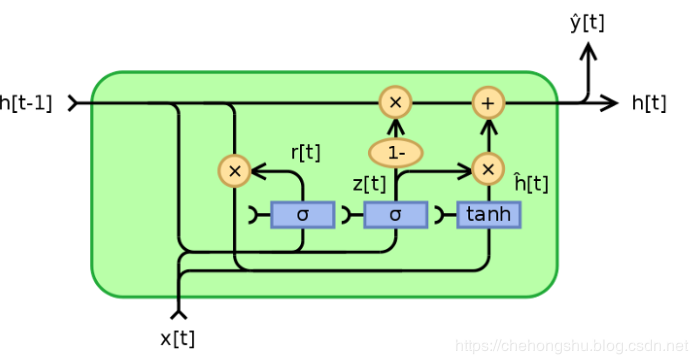
GRU(Gate Recurrent Unit)比LSTM少一个门控,它只有两个门控:重置门和更新门
 - 首先计算两个门控的参数
- $h_{t-1}'=r*h_{t-1}\qquad{(h'就是\widetilde{h}候选细胞)}$
- 首先计算两个门控的参数
- $h_{t-1}'=r*h_{t-1}\qquad{(h'就是\widetilde{h}候选细胞)}$
然后$h_t=z*h_{t-1}+(1-z)h_{t}’,y_t=W_oh_t\qquad(y_t只是为了方便输出和表示对h_t做的线性变换)$
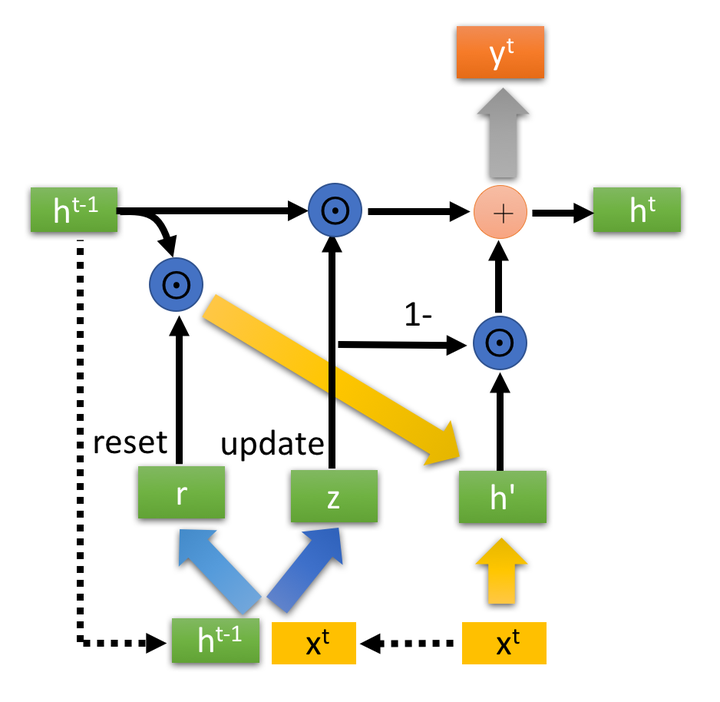
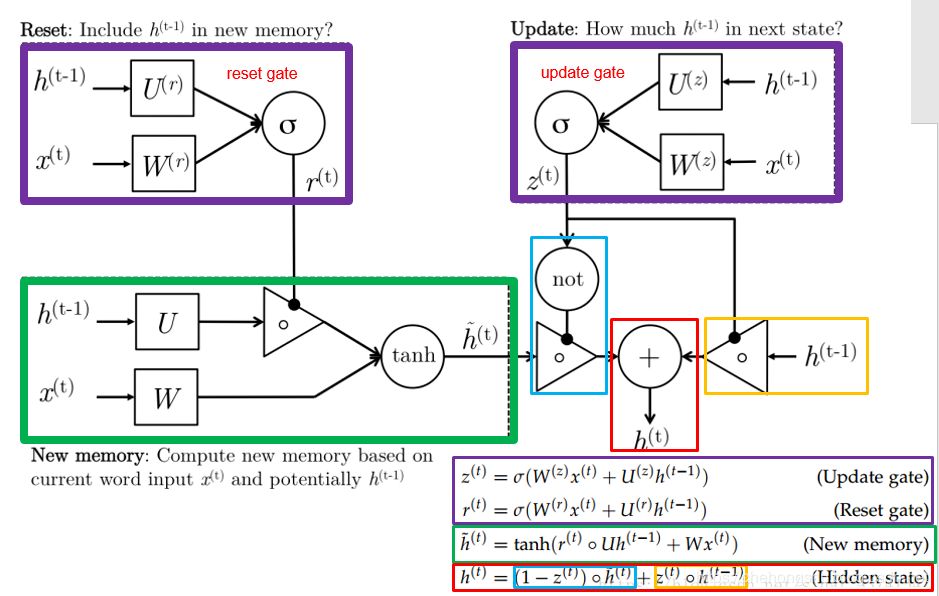
与LSTM的不同
- 1、GRU在信息合并的时候,只用了一组门控参数(更新门),比LSTM少了一组门控参数
- 2、GRU的输入只有两个,LSTM多了一个$c$。GRU摆脱了细胞状态并使用隐藏状态来传输信息。也就是两者对memory的控制不同,GRU直接传输给下一个单元,由下一个单元的
重置门来控制输入信息,而LSTM通过输出门来控制。我的理解是:GRU把这个单元的输出门和下一个单元的输入门合并在了一起 - 3、GRU的简化是用来降低复杂度的,所以在数据充足的情况下,LSTM稳定的时候精确度要比GRU好