自编码器
- 自编码器能够通过无监督学习,学到输入数据的高效表示,这一高效表示被称为
编码
何为高效的数据表示
如下列两组数据
- 40, 27, 25, 36, 81, 57, 10, 73, 19, 68
- 50, 25, 76, 38, 19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20
- 如果你觉得因为第一组数据短而好记,那么就错了,我们可以发现第二组数组的偶数后面是1/2,奇数后面是3倍+1(角谷猜想)
- 所以显然第二行的东西更容易记忆
- 自编码器通常包括两个部分,encoder(称为识别网络)将输入转换成内部表示,decoder(称为生成网络)将输入转换成输出,然后损失函数就是输出和输入之间的
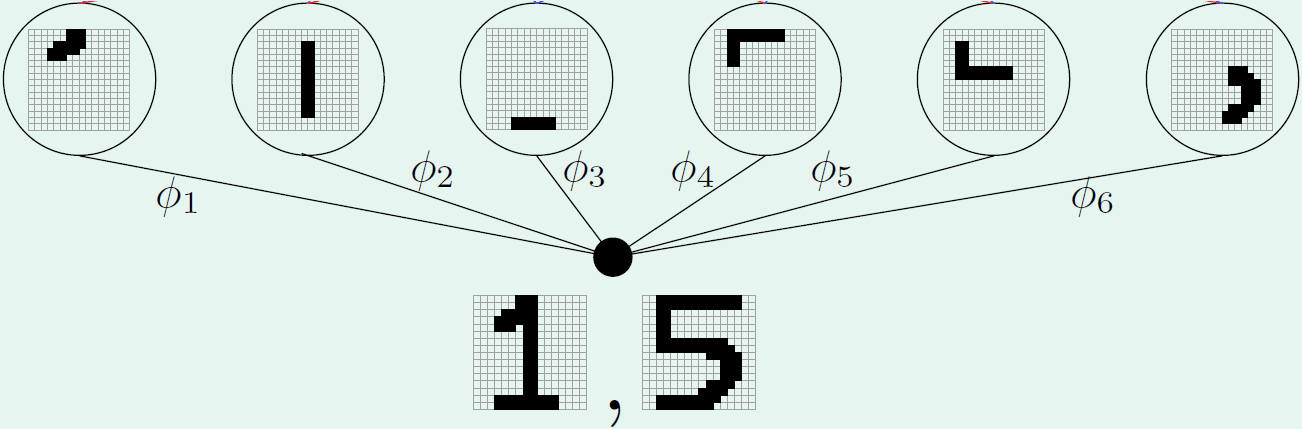
- 例如将上面的15拆分编码(encoder),最后再合成解码(decoder)
类型
不完备自编码器
- 内部表示的维度小于输入数据
- 可用神经网络的hidden layer来实现,只不过操作时比起平常不同的是要翻转一下,对维度操作
- 也可以用PCA来搞
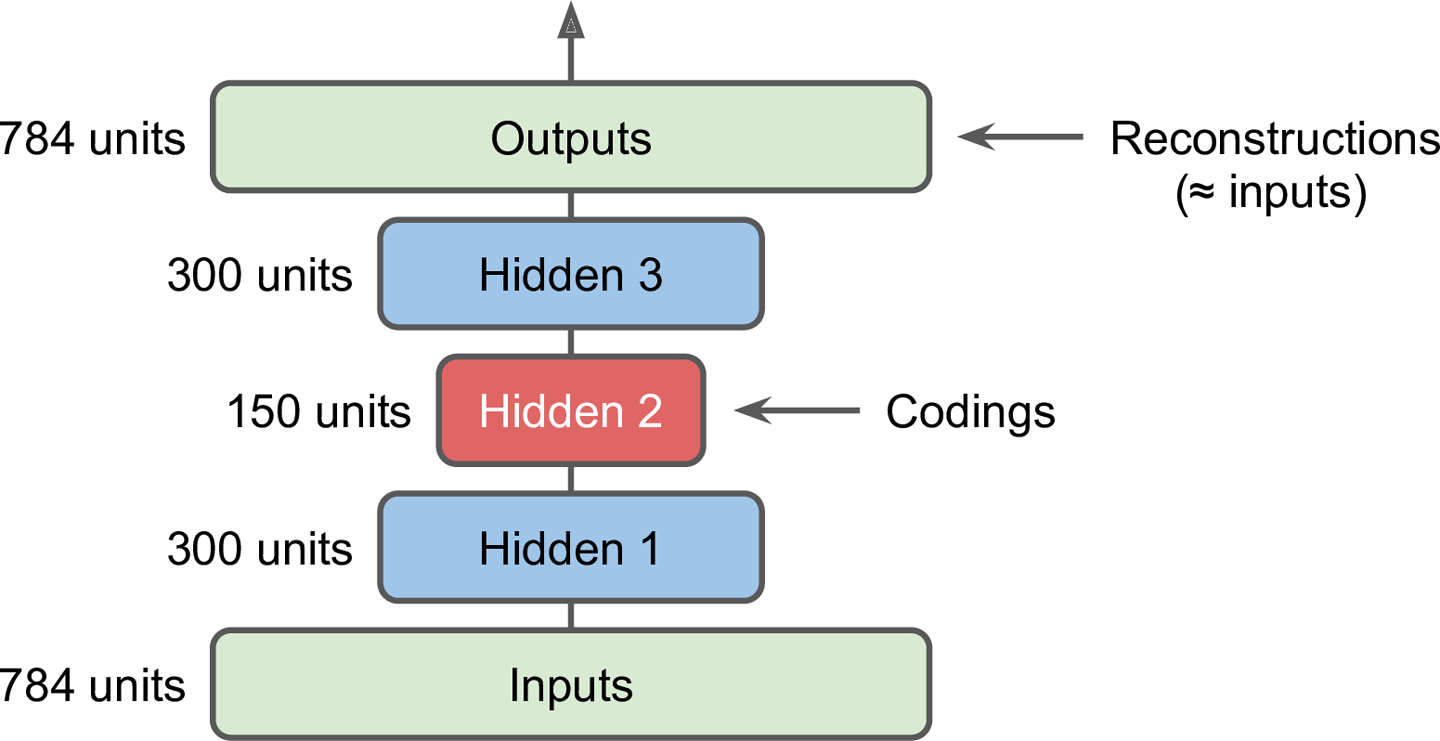
栈式自编码器(深度自编码器)
- 这种自编码器,有多个隐层,增加隐层可以学习更复杂的编码,但不能太强大,太强大重建数据太多可能还使得数据更复杂
- 栈式编码器的结构一般是对称的
捆绑权重
- 因为严格对称,一个常用的技术就是把decoder的权重捆绑到encoder,这样使模型参数减半,加快了训练速度和过拟合的风险
- 当然,bias不会捆绑
将深层栈式自编码器拆分
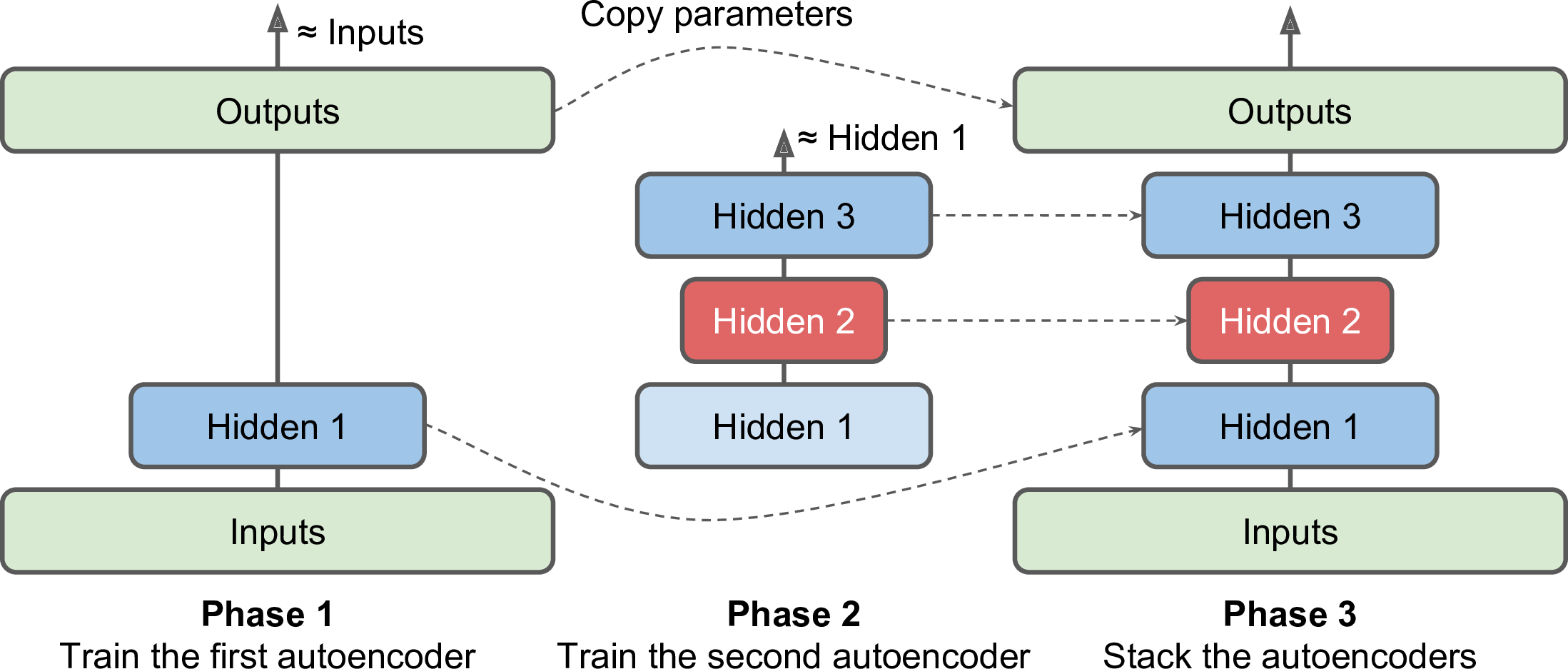
- 简单来说就是对输入构建一个自编码器,然后对于hidden layer的东西也搞一个自编码器,这样就可以用相同的参数搞很多个浅层的自编码器,还能使其更deep
增加操作
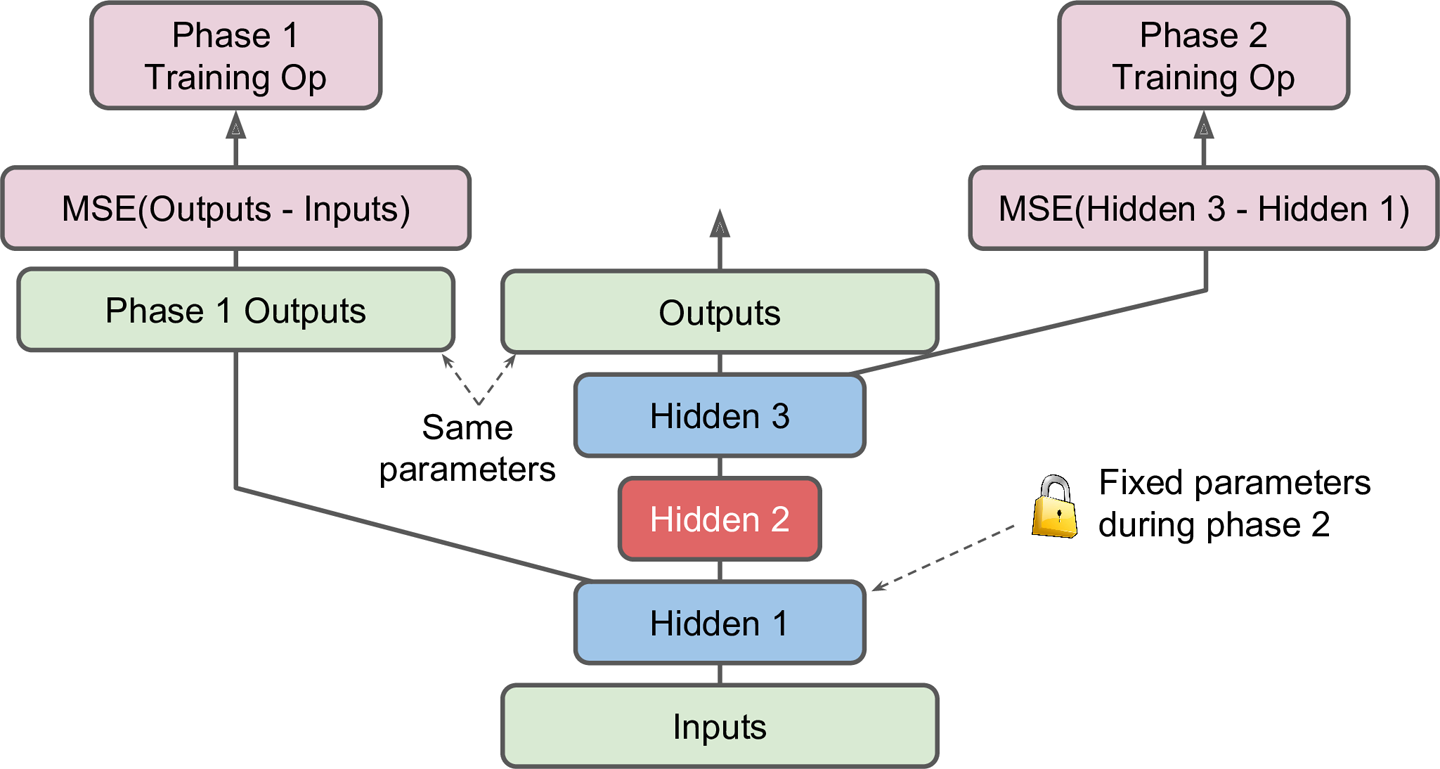
- 也可以不拆分,而是对一些hidden layer多搞一些操作
使用编码器来无监督预训练
当我们没有足够的标注数据的时候,一个普遍的解决方案就是找到一个类似任务的训练好的模型,然后使用这个模型的转化层。
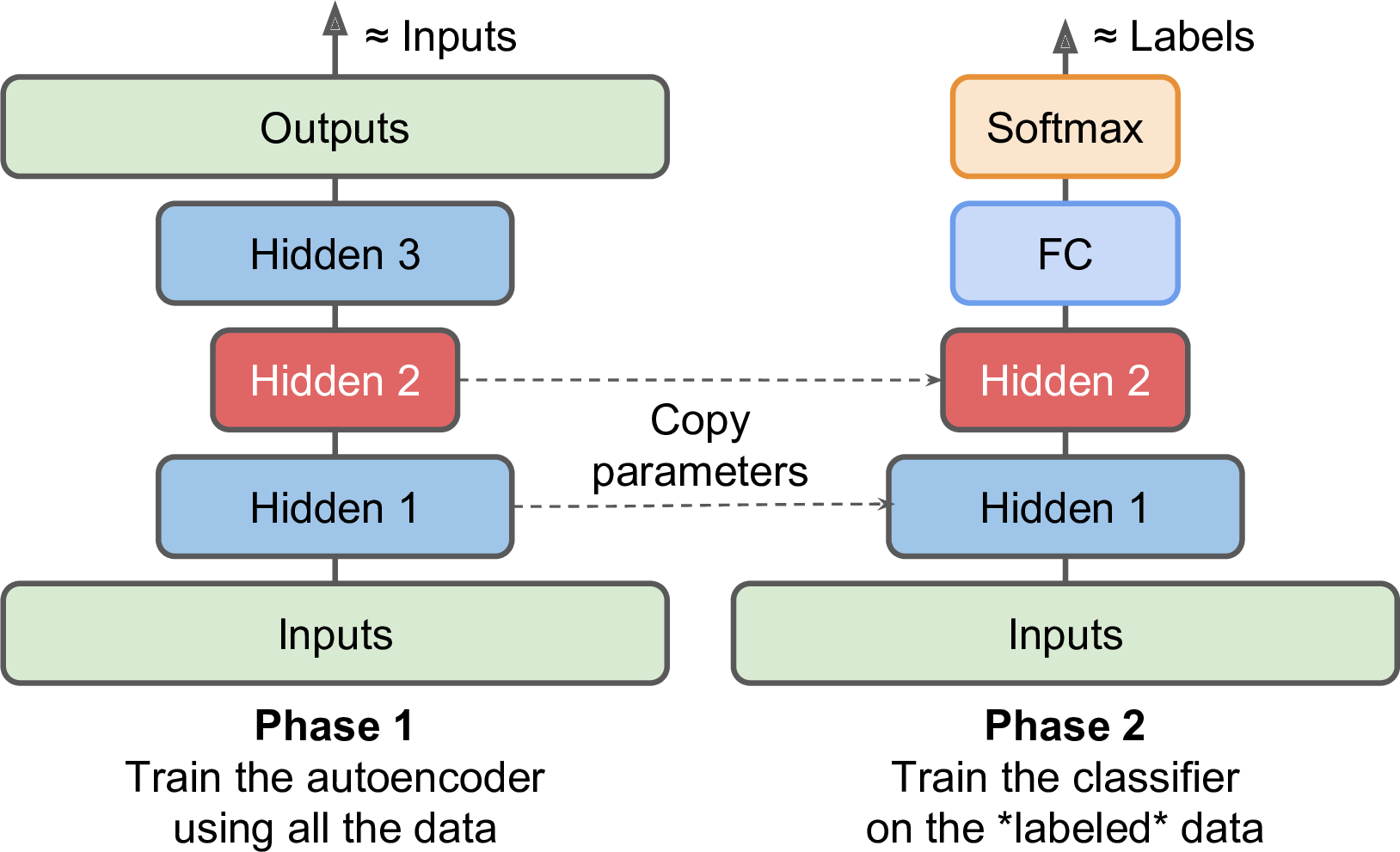
如上,我们用栈式自编码器来做预训练,然后把hidden layer做到底层来训练(感觉这个就相当于对不充足的数据学习了一个分布)
去噪自编码器
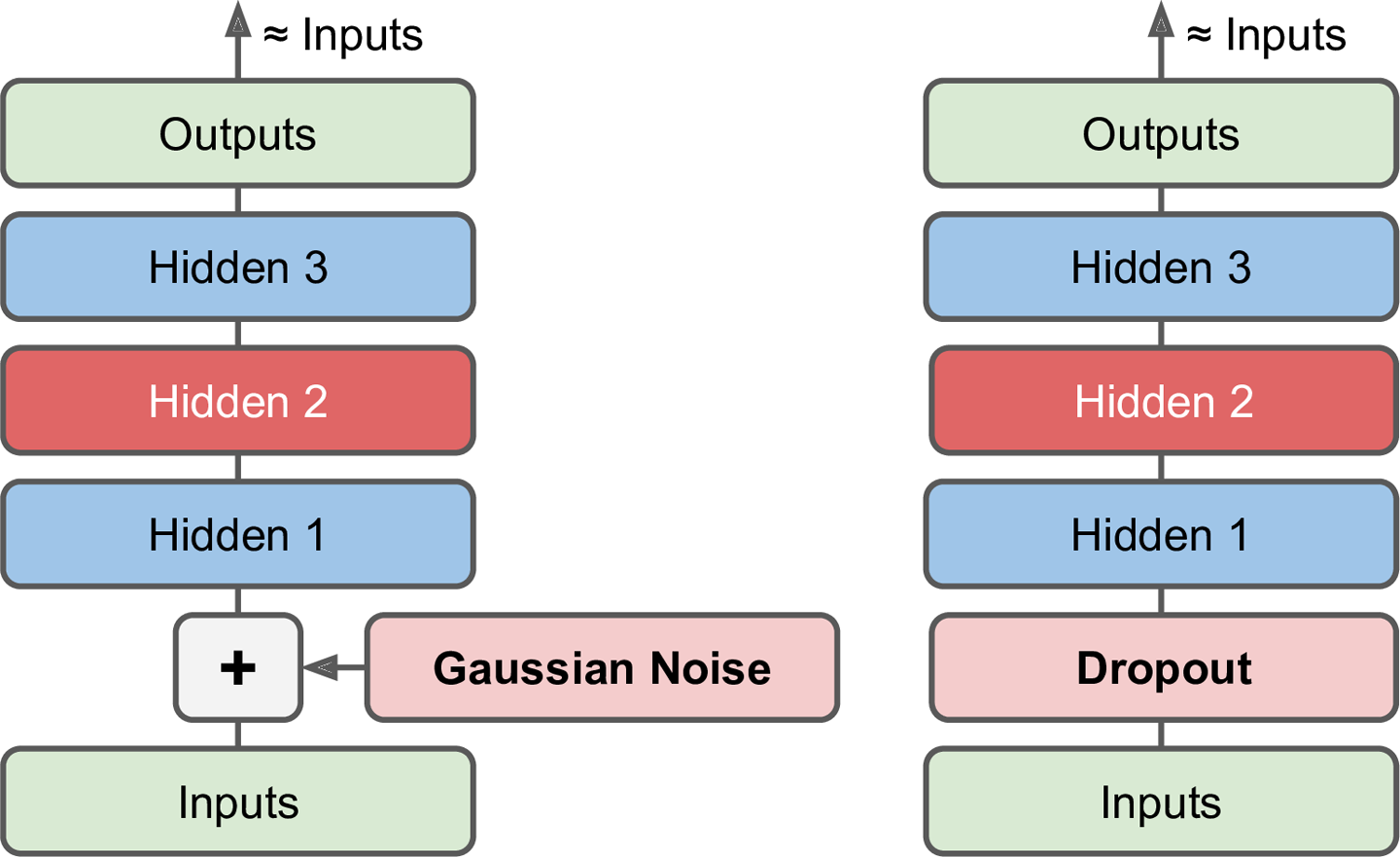
- 左边是高斯去噪,右边是dropout去噪