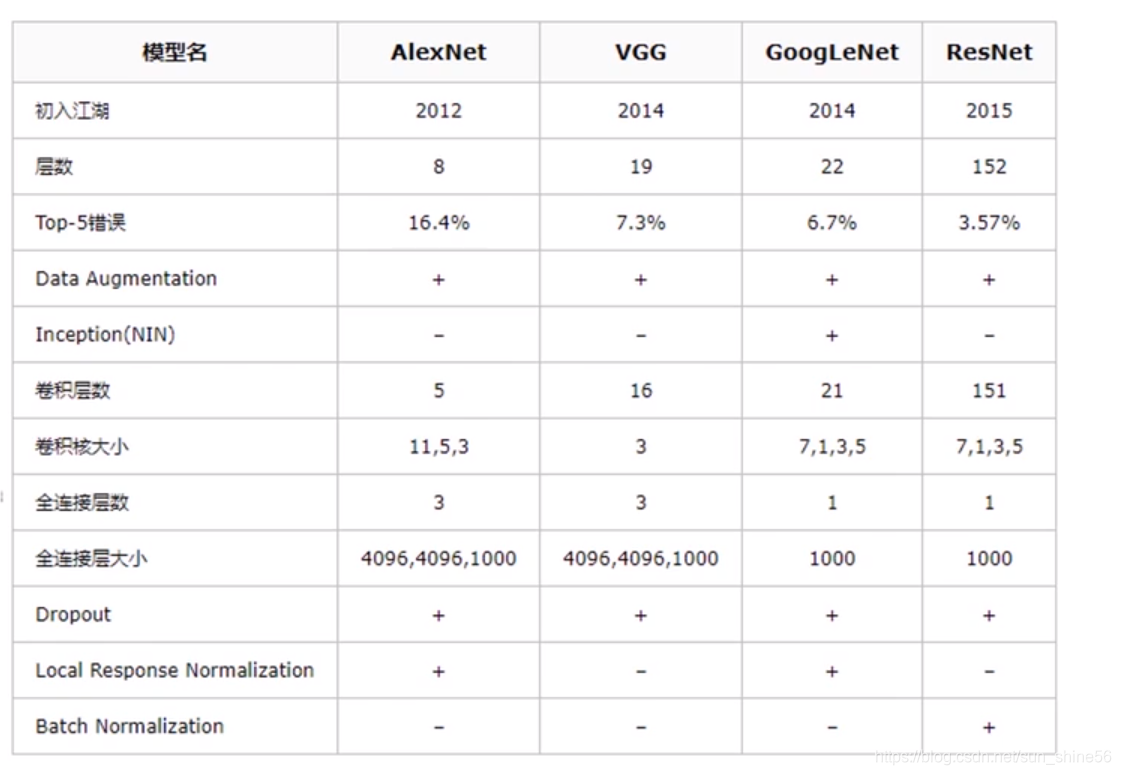
CNN发展史

早期铺垫
神经网络起源
- Hubel和Wiesel对猫大脑中的视觉系统的研究。
各种结构的铺垫
- 1980年,日本科学家福岛邦彦《Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position》
- 提出了一个包含卷积层、池化层的神经网络结构。
LeNet
LeNet几乎是所有CNN的开端
作者:Yann Lecun
首次形成经典结构,但是效果比起当时的SVM等不是很好。用于minst分类
输入层
- 输入根据各种白化,缩放等处理,是信息更好的处理
输入层疑问
- 1、为什么很多把图像处理成224*224(感性有道理的解释)
- 卷积是会掉分辨率的,这个掉的分辨率根据公式和stride有关:stride一般是用2的次幂的(毕竟1或者2好除)
- 然后$224=7*2^5$,那么我们在考虑后面的stride的时候就要宏观考虑一下了,以及考虑我们用的核都是(1,3,5,7,9),所以为这个。当然,我觉得不一定要是7,根据最后图像情况而定,但是很多这样搞就习惯了
卷积层
卷积(卷积核)
线性、平移不变性运算,在输入信号执行局部加权组成。根据所选择的
权重集合(即所选择的点扩散函数)的不同,来揭示输入信号的不同性质。具体特点
1、通过卷积运算,使得原信号特征增强,并且降低噪音
a.不同的卷积核能提取不同的特征
1、边缘检测(横向同理)
2、sobel滤波(横向同理)
3、scharr滤波(横向同理)
b.参数共享减少参数(就是不用每个地方,像全连接那样去弄一个参数)
点扩散函数
频域中,与点扩散函数关联的是调制函数——说明了输入的频率组分通过缩放和相移进行调制的方式。
==因此,选择合适的kernel对输入信号中包含最显著和最重要的信息而言至关重要。==



激活函数(以下与发展史不太有关)

由于卷积是线性的,要拟合一些非线性的模型需要一些非线性的运算来拟合,所以就有了激活函数
饱和的定义

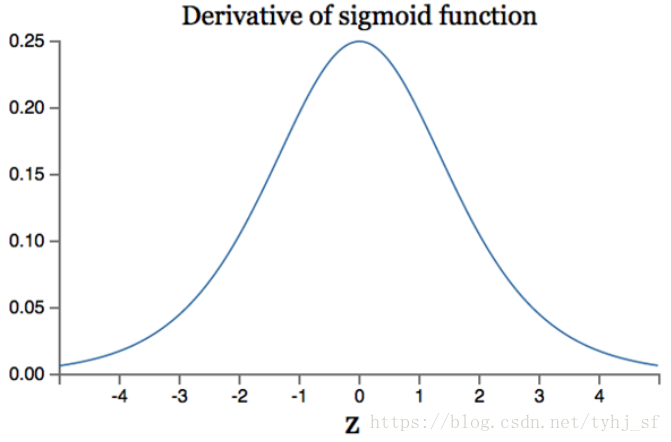
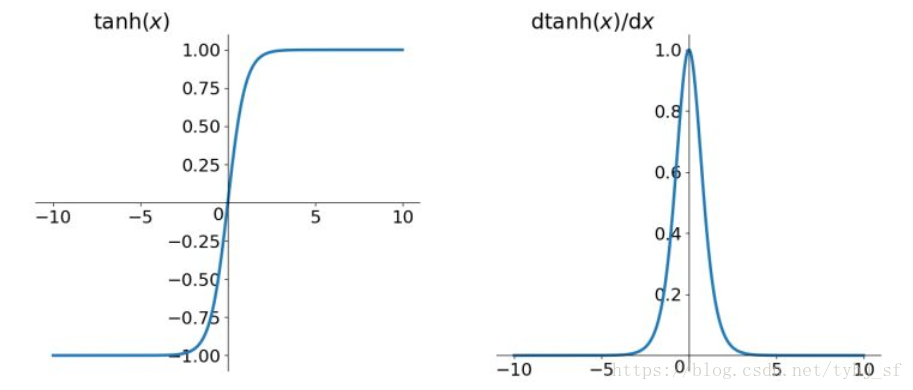
sigmoid($\sigma(x)$左端->0,右端->1,两段饱和)
现在已经较少使用(主要是不在隐藏层使用,也就在输出层是二分类问题的时候使用)
优点:
- 可作为概率输出
- 平滑,易于求导
缺点:
两边饱和,所以接近饱和之后就会有梯度消失的问题
输出都是正数,所有数据改变的方向都相同,会引起“Z字抖动”(Z字下降,收敛的很慢)
- 为什么方向相同,假设$z=f(\sigma(x))$,导数为$f’(\sigma(x))\sigma’(x)$,f的导数和$\sigma(x)$的正负有关,因为输出全为正数,所以整体方向相同
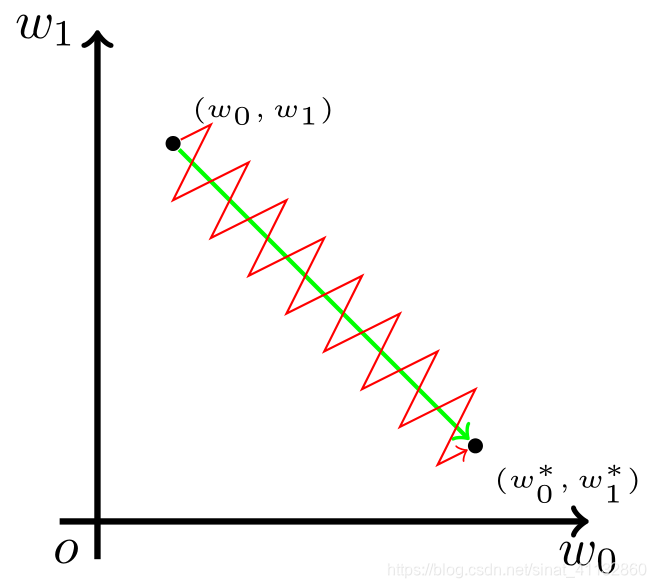
计算耗时
tanh($2\sigma(2x)-1$)
- 优点:
- 解决了sigmoid的零均值问题
- 缺点:
- 两边饱和,仍存在梯度消失
- 计算耗时
- 优点:
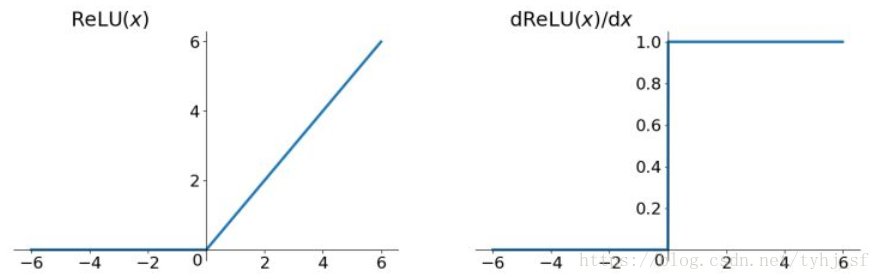
ReLU(max(0,x))
- 优点:
- 正区间上解决了梯度消失问题
- 计算速度快
- 收敛速度比上两者快
- 就神经网络而言:它是分段线性函数,能增加网络非线性性,要把网络做的很深,这正好迎合了网络要深的要求,更深泛化更好
- 缺点:
- 输出不是零均值
- 神经元坏死现象:只要输入负值,那么输出就是0,就导致后面的网络输入都是0,造成大面积坏死
- 坏死造成因素:
- 1、不幸的初始化
- 2、学习率过高,参数更新到负数—>可用adagrad等调节lr
- 坏死造成因素:
Leaky ReLU/PReLU($max(\varepsilon x,x),0<\varepsilon<1$)
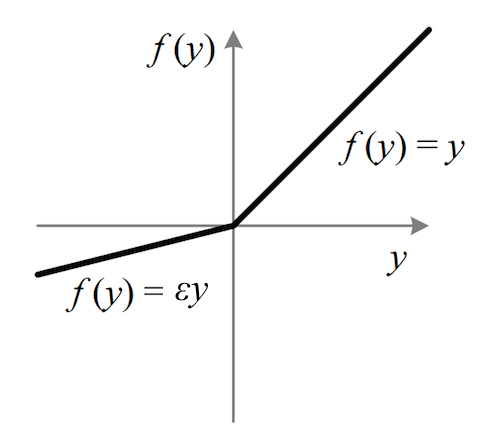
显然是对Dead ReLU Problem的改进
==升级版:PReLU==
- 即把每个$\varepsilon$当做神经元的参数来搞
EReLU($max(x,\alpha(e^x-1))$)

- 有一定的抗坏死能力,但是还是有梯度饱和和指数运算的问题
RReLU
$$
y_{ji}=\begin{cases}x_{ji} (x_{ji}\geq 0)\\ a_{ji}x_{ji}(x_{ji}\leq0) \end{cases}\\ \\ a_{ji}\text{~}U(l,u),l<u(l,u \in[0,1))$$
GReLU、Swish。。。再说XD
卷积层疑问
1、为什么卷积核的边长都是奇数*奇数
- 1、中心点理论:偶数*偶数没有中心点
- 更容易描点:没有中心点那得到的东西要放在哪里,如果一下放四个一样的肯定影响特征的提取且参数两量增加;如果放一个,得到的特征分布会偏移(比如4*4的)
- 为了各种中心的统一
- 2、padding理论
- 如果为奇数加padding,那么得到的值中心对称;若是偶数只得到一个值则会偏移
- 根据卷积结果结算公式,当$stride=1,padding={(k-1)\over 2}$,只有在k为奇数的时候,才能使得图片大小与原来相同
- 1、中心点理论:偶数*偶数没有中心点
2、关于卷积核是正方形
1、首先统一的就是中心点理论,输入的图片要关于卷积核中心对称,正方形较好;同时还考虑到padding等的方便形
2、非对称的卷积核会有
混叠错误,加了padding之后还有信息丢失和噪声引入3、==但是长方形的核也是按轴对称的==:所以其实是可以用长方形的,有时在长条形的图片上用长方形会更好一点
4、==关于可变形卷积==:
方形的核是针对这个像素点的完全周围信息来考虑的,而可变形的卷积核是根据任务需要自适应的调整



如上(环境,小物体,大物体),只管效果就是根据图像内容的不用发生自适应的变化
暂时还未深入研究
3、新的卷积核(不在发展史讨论内)

池化层
- 是一种形式的降采样
- 为什么需要pooling
- 1、增大感受野——感受野就是一个像素对应回原图的区域大小,增大感受野能提取更加多的特征
- 2、平移不变性——我们希望目标有些许位置移动,能得到相同的结果,因为pooling不断抽象了区域的特征而不关心位置,所以一定程度增加了平移不变性——也就意味着即使图像经历了一小段平移,也会产生相同的(池化)特征
- 增加这个性质有什么用呢?——比如在处理图像的时候,两个相同的内容虽然有些小差别,但是提取的特征相同
- 3、减小参数和优化难度
- 种类
- 最大池化
- 最大池化可以更好的保留纹理的特征
- 却打断梯度回传
- 平均池化
- 平均池化可以更好的保留数据的特征
- 却会丢失细节
- 最大池化
- 据说已有代步长的卷积不用池化
全连接层(fc)
输出层

AlexNet
- 准确率大幅度提高,让CNN兴起
- 作者Hinton

比之前的优化处理
增加了ReLU,优点参见上面
增加了dropout层,防止过拟合,这个成为以后fc层的标配
通过数据增强,减少过拟合
引入标准化层:通过放大那些分类贡献较大的神经元,来抑制那些贡献较少的神经元,用过局部归一化来达到作用(
LRN局部响应归一化层)GPU并行
ZFNet
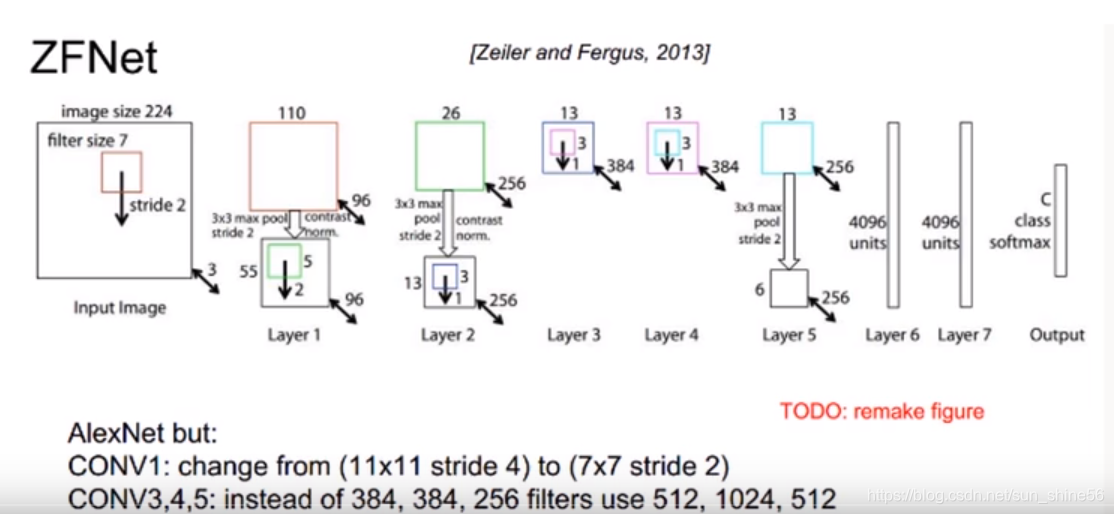
- 在AlexNet上做了小小的改进
- 调整第一层卷积核大小为7*7
- 设置卷积参数stride=2
- 通过更小的kernel和stride来提取更多的信息,同时加多了核的数量也使网络更深
最重要的是–对CNN的可视化解释
- 作者从可视化的角度出发,解释了CNN有非常好的性能的原因
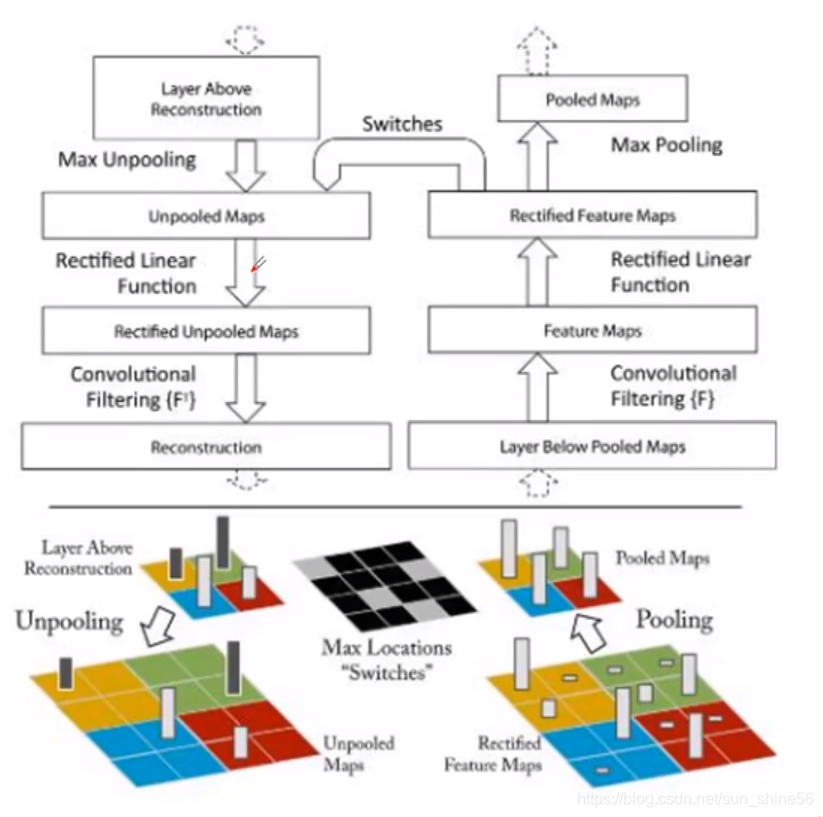
- 有半边是我们的一个正常的神经网络的数据流向:
- 对于一副输入图像,我们通过pooling层来进行下采样,再通过卷积层进行特征提取,通过ReLU层来提取非线性表达能力
- 不过,对于最后的数据结果,我们怎么还原成图片呢
- 当然,不可能100%还原,因为每次pooling的时候都会有数据的丢失,所以我们在可视化的时候,更重要的是对图像的特征语义进行更高层次的解析
- 通过对输出层,上采样,可以得到与原始图像一样大小的特征图,观察这些图得出结论
- 特征分 层次体系结构
- 深层特征更鲁棒(区分度高,不受图片微小的影响)
- 深层特征收敛更慢
- 通过对输出层,上采样,可以得到与原始图像一样大小的特征图,观察这些图得出结论
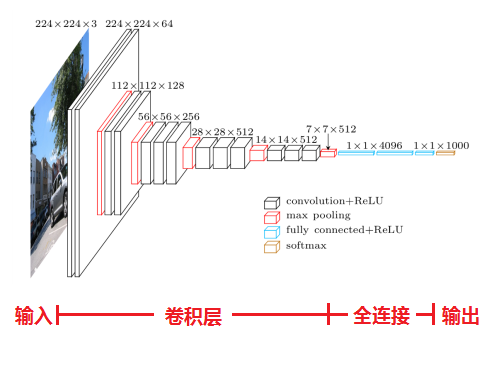
VGGNet
作者:牛津大学和Google Deepmind共同设计
特点:全部使用1X1、3X3的conv kernel和2X2的pooling kernel
优点:
通过小的核来不断的增加网络结构来提高性能,但是并不会把参数量搞大(证明增加深度能够提高性能)
- 如2个3X3的核$\Leftrightarrow$ 5X5的核,3个3X3的核$\Leftrightarrow$7X7的核
- 而3个3X3的参数量只有7X7的一半左右,原因类似1X1的核减小参数的方法,用小的核制造出新的channel显然会小一点
- 而核小量多,导致非线性层变多,特征学习能力更强
- 2X2的pooling也是一样,每次使得channelx2而feature map宽高减半,通道数增倍
引入
1X1的kernel特征图的空间分辨率单调递减,特征图的通道数单调递增,这样更好的把HxWx3的图像转化为1x1xC的输出
- 而在初始的时候通道数变多,能提出更多的特征
先训练A网络,在用A网络的权重来初始化后面的更复杂的网络
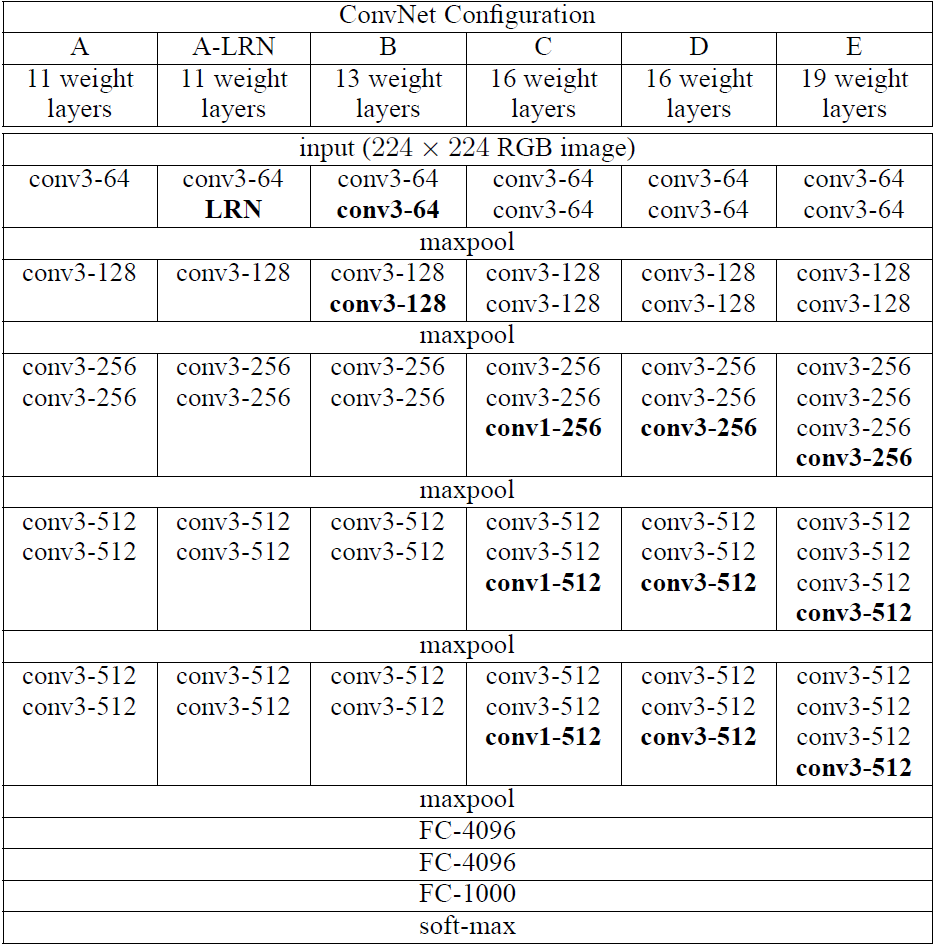
- 作者提到用LRN层无性能增益,所以之后没有用过LRN
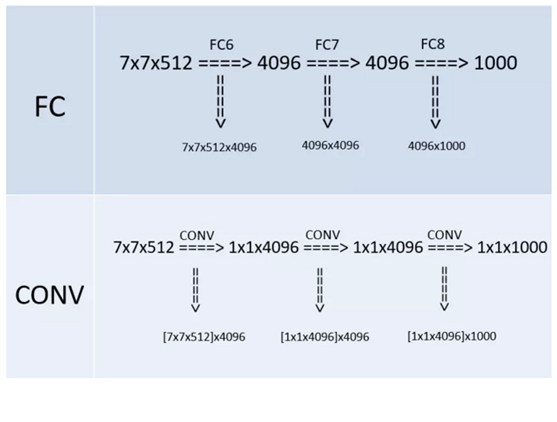
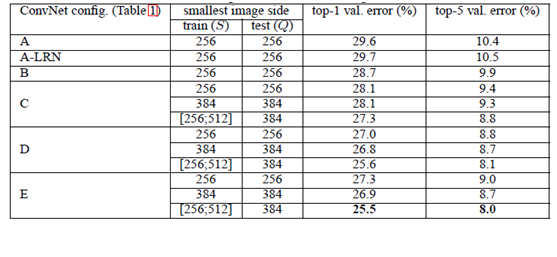
缺点
- 耗费资源很大,所以我们用的时候是直接调用公开的预训练参数
GoogleNet
- 不仅考虑了深度还考虑了宽度,进一步增加了网络的深度和宽度,但是参数量更低
Inception
- 一种NIN结构
V1
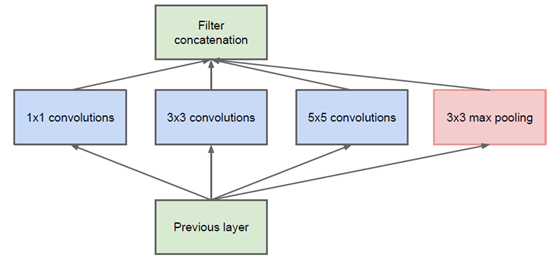
该结构将常用的卷积和池化,
堆叠(尺度相同,将通道相加)在一起- 一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性
- 这样的结构可以提取很多细节的信息,加了pooling之后还能减小空间大小,降低过度拟合,每个conv配上个ReLU,增加非线性性
然后使用经典的1x1 conv来减参,增激活
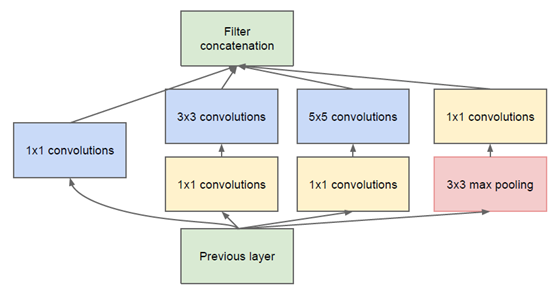
为什么1x1的conv放在pooling的后面,而其他的放前面
- 我的理解是先用pooling提取特征再做变换,虽然会导致部分特征缺失
最后变为
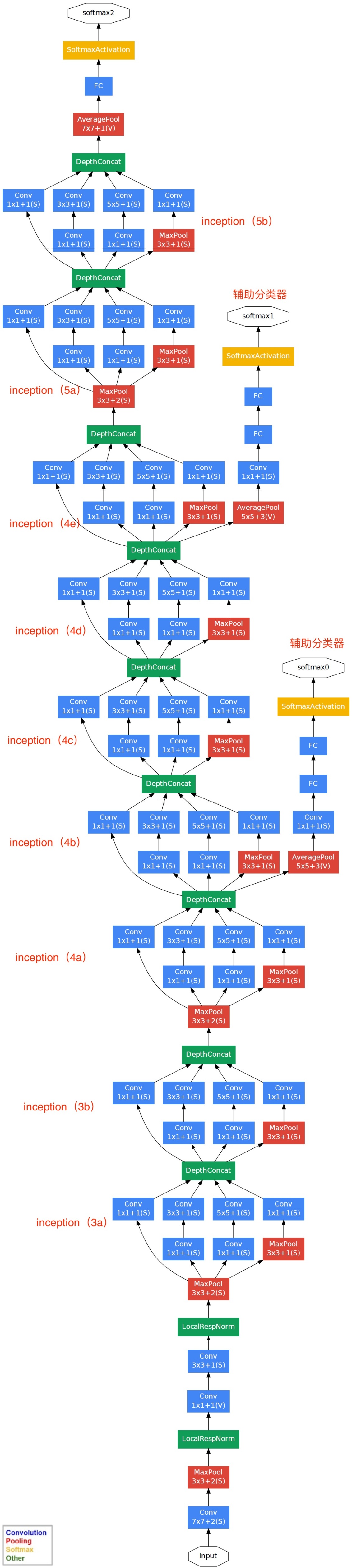
- 学习了VGG的模块化
- 网络最后采用平均池来代替全连接层,该想法来自于NIN,可以提高精度(我自己还有待研究)。实际上,为了方便操作还是加上了一个fc
- 虽然没有了fc,但是网络中还是使用了dropout
- 为了避免梯度消失,网络额外增加了辅助的softmax用于向前传导梯度
- 辅助分类器是将中间的某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中
- 这样有利于模型分融合,同时给网络一个梯度信号,也提供额外的正则化
- 当然,测试的时候是没有softmax的
- 只是用到Inception v1就能有较好的效果
V2
- 由于单纯的堆叠会使计算效率明显下降,所以要研究如何不增加过多的计算量的同时提高网络的表达能力
- 这个版本的解决方案就是修改Inception的内部逻辑,提出了特殊的卷积计算方式
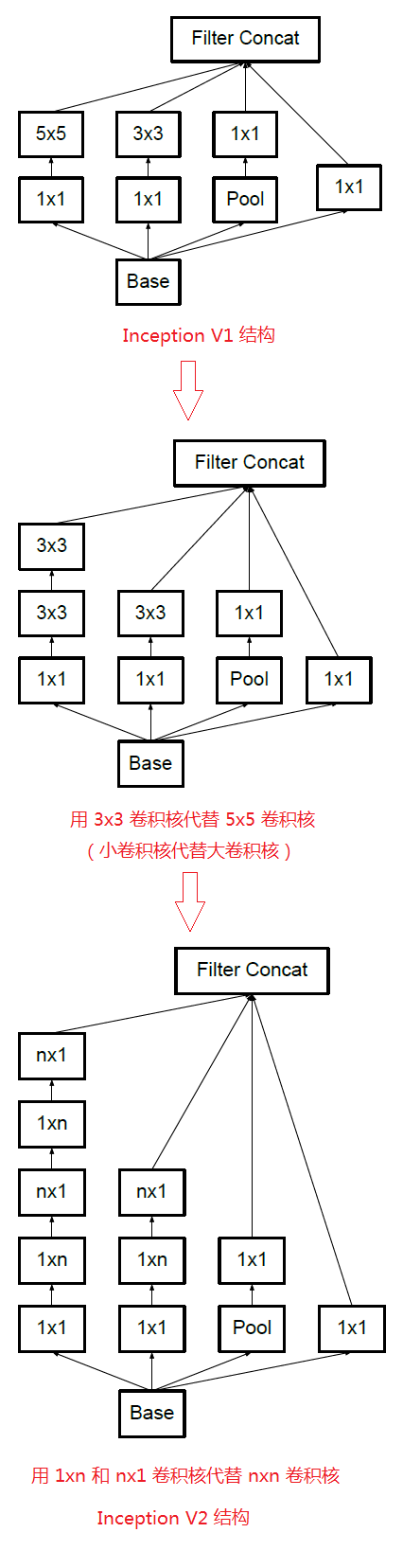
卷积分解
大卷积核有大的感受野,但是也会有更大的参量—>所以我们打算在保持感受野的同时减少参量
但是这样会导致表达能力下降吗? 目前大量的实验表明:不会有什么损失
所以构造出了一个nx1的卷积。如下图,用2个3x1取代3x3
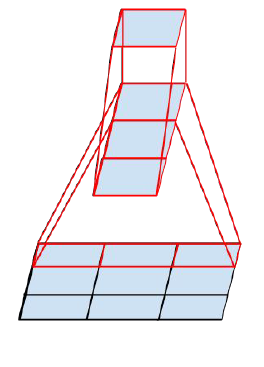
因此,任意一个nxn的卷积都能用nx1后接一个1xn的卷积代替
所以把Inception V1的5x5的结构也换成3x3的结构,然后再拆成1x3和3x1的结构
降低特征图的大小
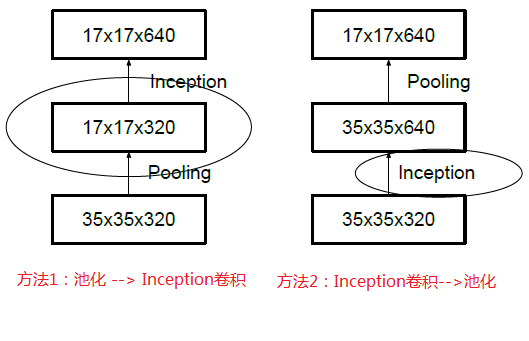 –
–
上面两个方法都可以减小特征图的大小
- 但是方法1会导致特征缺失
- 方法2是正常的缩小,但是计算量很大
- 但是方法1会导致特征缺失
所以我们为了保持特征表示并降低计算量,将网络的结构使用下图,使用两个并行化的模块来降低计算量
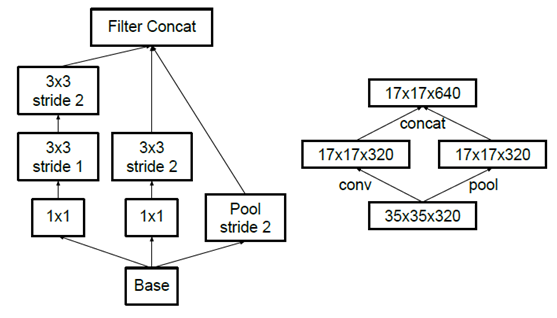
- 就是简单的分成两个部分XD
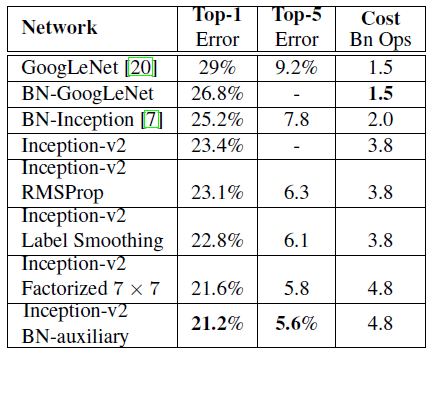
- 正确率较旧模型有所提升
V3
- 就是参照V2的把各种nxn的给拆开了
- 然后网络输出从224x224变成299x299
(为什么拆开在之前不干完呢,可能是一些其他原因,在当时干的时候模型并没有提升,或是忘了???)
V4
- 结合了残差模块
ResNet
- 作者:何kaiming团队
- 特点:
- 核心单元简单堆叠
- 跳连结构解决网络梯度消失问题
- 最大池化代替fc层
- BN层加快网络速度和收敛时的稳定性
- 加大网络深度,提高模型的特征抽取能力