R-CNN
创新(虽然已是经典)
- 第一次把CNN放在物体检测的算法,采用CNN网络提取特征,从
经验驱动的人造特征范式HOG、SIFT到数据驱动的表示学习范式,提高了图像特征的表达能力 - 采用大样本下有监督的预训练,在加上下样本微调的方式解决小样本难以训练甚至过拟合的问题
流程
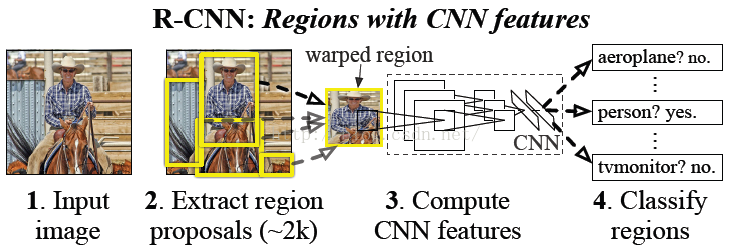
1、找出候选框(region proposals)
1、首先,先经过selective search搜索出一些矩形框
2、我们要把矩形框变成227*227的CNN输入框
(1)各向异性缩放
- 这种就是直接缩放,这种当然可以,但是不好,会造成图像扭曲
(2)各向同行缩放
- (1)(各向同性)直接把候选框边界扩张,如果到了图像的边界那么就用均值填充,如下图(B)
- (2)(各向同性)超过边界的地方用均值填充,如下图(C)
- (3)(各向异性)直接缩放,如下图(D)
- (4)处理前现在图像旁边加些padding,上行为padding=0,下行为padding=16
- 说了怎么多其实很显然,直接缩放加padding=16精度最高(作者经过了最终实验)
论文提取了2000个框

2、CNN预训练(pre-train)与调优(fine-tunning)
- 分为有监督预训练和无监督预训练
- 无监督
- 如自编码器,DQM
- 有监督
- 迁移学习,这里就是最简单的把图像识别模型套过来
- 本文就是用的有监督
- 无监督
- 为了让引入的模型适应新的任务(检测任务)和新的领域(变形的窗口),我们要进行调优
- 假设要检测的目标有n个,加上背景就是n+1个
- 我们把引入的模型的最后一层替换成n+1个神经元,然后对所有的候选窗口预测,如果$IoU\geq 0.5$那么就是正例,否则是反例(这里的正例就是检测目标,反例就是背景)
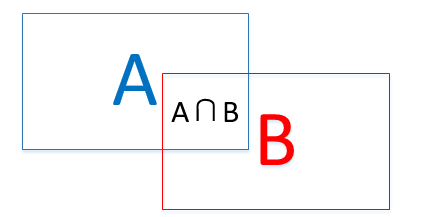
- $IoU$全称交并比,就是两个集合(区域)的交与并的比值,如下中间的比所有的
- 每次训练的时候32个正例样本,96个负例样本
- $IoU$全称交并比,就是两个集合(区域)的交与并的比值,如下中间的比所有的
3、CNN提取特征
- 用CNN提取出4096维的特征(这就是图像检测在此文章的进步之处,比人工经验特征少两个数量级)
4、SVM分类
- 论文中是把2000×4096维的特征好权值矩阵4096×20相乘得到2000×20的针对每个类别的得分
- 由于多分类的SVM
直接法(就是直接在目标函数上修改得到一个最优化问题)。这样的方法计算复杂度较高,所以我们采用间接法。这里是最简单的用n个SVM - SVM中$IoU\geq 0.3$的认为是正例,反之为负例
- 由于正例的个数较少,而且要为了识别一些只拍到了一部分的图片
- 由于多分类的SVM
先介绍两个为了解决目标检测的老问题的(样本不均衡+低召回率)方法
非极大抑制(NMS)
顾名思义:抑制不是极大值的与元素,可以理解为局部最大搜索
有时会遇到以下的情况,同一个车辆目标会被多个建议框包围,这时候需要非极大抑制来去除得分较低的候选框,以此来判别那些矩阵框没有用,且能加速时间
1、将SVM得到的分类概率排序,假设排序后从小到大的循序是:A,B,C,D,E,F,G
2、倒序判断(从大到小判断),判断比他概率小的候选框与它的$IoU$是否大于某个阈值
3、然后把那些把那些找出来的候选框删掉:如对于F来说,B、D和他们的$IoU$大于某个阈值,那么我们就把BD踢掉
4、重复以上步骤直至停止

hard negative mining method
- 难负例挖掘算法:为解决当正负样本不均衡的时候,而负例分散、代表性又不够的问题
- 所以这样显然的有低召回率
- 所以为了让模型正常的训练,我们要通过某种方法抑制大量的简单负例,挖掘难例的信息。座椅这个算法就是在训练的时候,尽量多挖掘难负例假如负样本集,这样会比简单负例组成的负样本集效果好

- 算法思想很简单,形象的说就是弄一个错题本,然后把弄错的再放进去训练
- 注意这些错的东西都是负例,所以叫做
难负例
- 注意这些错的东西都是负例,所以叫做
- 结合上面两个方法训练SVM
- 现在问题来了,为什么要使用SVM来分类,而不是直接微调后的网络来个softmax
- 当然这种方法可以,但是这样的效果没有用SVM好
- 微调的定义不强调精确位置,CNN容易对小样本拟合,需要大量的训练数据,要求宽松,$IoU\geq0.5$即为正例,而SVM适合小样本训练,$IoU$要求更严格,SVM要$0.3$。这是正负样本定义的问题
- 当然这种方法可以,但是这样的效果没有用SVM好
5、bounding-box回归(边框回归)
基于错误分析:对候选框进行校正,使得精度更高
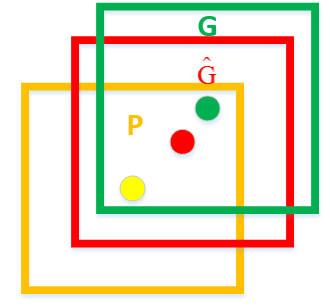
黄色的框是候选框,绿色的框是Ground Truth,红色的表示回归后的预测框
有一个假设:
IoU>0.6后两个框可以认为是线性变换$$
G=(G_x,G_y,G_w,G_h)\qquad 坐标x,y,宽,高\
定义四种变换函数d_x(P),d_y(P),d_w(P),d_h(P)\
d_x,d_y是平移变换,d_w,d_h是缩放变换\
d_(Z)=w_^T\phi_5(Z)\qquad w_^T是所需要学习的回归参数,\phi_5(P)是网络Pool5\层特征的线性函数\
\hat G_x=P_wd_x(Z)+P_x\
\hat G_y=P_hd_y(Z)+P_y\
\hat G_w=P_wexp(d_w(Z))\
\hat G_h=P_hexp(d_h(Z))\
Loss=argmin\text{ }\sum (t_-\hat w_^T\phi_5(Z))^2+\lambda||\hat w_||^2\
回归目标t_*由训练输入对(P,G)计算而来\
t_x=(G_x-P_x)/P_w\
t_y=(G_y-P_y)/P_h\
t_w=log(G_w/P_w)
t_h=log(G_h/P_h)
$$然后我们训练$w$即可